
7 Powerful Reasons Why Understanding BERT Token IDs Will Transform Your NLP Skills
What Are BERT Token IDs? A Simple Explanation
If you’re exploring natural language processing (NLP), you’ve probably heard of BERT, Google’s powerful language model. But you might be wondering: how does BERT actually read and understand text? The answer lies in something called BERT Token IDs.
In this article, we’ll demystify how BERT converts human language into numbers using token IDs and explain it with a relatable sentence:
“A puppy is to dog as kitten is to”.
What Is BERT? (Quick Refresher)
BERT stands for Bidirectional Encoder Representations from Transformers, and it was introduced by Google in 2018. It’s a deep learning model that understands the context of a word based on surrounding words — not just one direction (like left to right), but in both directions.
🔗 Read Google’s original BERT announcement for more technical details.
BERT powers many modern NLP tools like chatbots, search engines, and sentiment analysis engines. But before it can “understand” anything, it first needs to convert text into something numerical. That’s where token IDs come in.
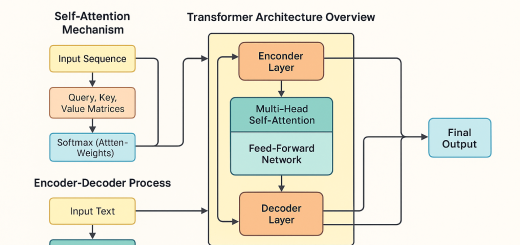
The Transformer Architecture in AI: Explained with Examples & Flowcharts
What Are Tokens in BERT?
Before diving into token IDs, let’s talk about tokens. In NLP, a token is simply a piece of text — usually a word or subword — that a model processes.
For example, in the sentence:
“A puppy is to dog as kitten is to”
The tokens would be:
-
A
-
puppy
-
is
-
to
-
dog
-
as
-
kitten
-
is
-
to
However, BERT adds special tokens to the beginning and end of every sentence:
-
[CLS]at the start (used for classification tasks) -
[SEP]at the end (used to separate sentences)
So, the full tokenized version becomes:[CLS] A puppy is to dog as kitten is to [SEP]
What Are BERT Token IDs?
Now comes the magic part: BERT converts each token into a token ID — a number that uniquely represents the token in its vocabulary.
Here’s how our example sentence looks once tokenized into IDs:
| Token | Token ID |
|---|---|
| [CLS] | 101 |
| A | 1037 |
| puppy | 17022 |
| is | 2003 |
| to | 2000 |
| dog | 3899 |
| as | 2004 |
| kitten | 18401 |
| is | 2003 |
| to | 2000 |
| [SEP] | 102 |
Why Convert Words into Token IDs?
There are three key reasons:
-
Computers Don’t Understand Text Natively
Neural networks need numbers, not words. Token IDs bridge that gap. -
Efficient Processing
By using fixed-length IDs, BERT can handle varying sentence lengths uniformly. -
Handles Unknown Words Gracefully
If a word isn’t in the vocabulary, BERT splits it into known subwords. For instance, “unhappiness” might be split into “un”, “##happy”, and “##ness”.
How Token IDs Power NLP Models Like BERT
Once a sentence is transformed into token IDs, these IDs are passed through several neural network layers in BERT. The model then learns context, meaning, and relationships between words.
For example, in:
“A puppy is to dog as kitten is to [MASK]”
BERT can infer that the masked word should be “cat” — all by understanding token patterns and context using token IDs.
Visualizing Tokenization: A Learning Boost
Seeing how a simple sentence gets broken down into tokens and then into numbers can help solidify the concept. (Image below illustrates this!)
Conclusion: Why BERT Token IDs Matter
Understanding BERT Token IDs is fundamental if you’re diving into natural language processing. These IDs are the numerical backbone that lets BERT convert text into a format it can understand and analyze.
Whether you’re building a chatbot, summarizing articles, or classifying text, knowing how BERT tokenizes sentences gives you deeper insight into how AI understands human language.








Recent Comments